Data-driven decision making has become an important topic among law firm leadership as they notice the success of progressive law firms that have established effective data management programmes that have paved the way for artificial intelligence, machine learning, and search systems that support such decision making.
As firms consider implementing similar programmes, they find themselves wrestling with the challenges of how best to manage their own data and whether to adopt a more traditional data warehouse or a more modern data lake system.
The challenges of managing law firm data
Managing data proficiently is no small task for law firms, especially because source data is typically decentralised and stored separately in independent systems with limited, or even no ability to exchange information. To overcome this fragmentation, data must first be consolidated and centralised in a master data platform as illustrated below.
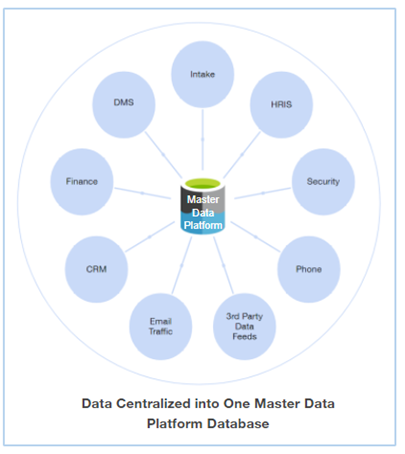
Once a decision has been made to invest in data centralisation, a firm finds itself debating the relative merits of the two options for the master data platform: data warehouse or data lake.
Data warehouses and data lakes
Data warehouses have been around since the mid-1980s. By the end of the last century, they had become widely adopted by large-scale businesses to store data to support business intelligence needs. Data warehouses are specialised databases that are carefully planned to capture and supply data that someone has decided is ‘needed’ for business analytics and reporting. These platforms contain data that is copied from source systems and is cleansed and validated during the copying process in accordance with carefully defined business rules. For instance, for dashboards that allow for financial reporting, financial formulas such as profitability and realisation can be pre-calculated, hours of effort can be categorised by attorney or matter, and then summed up by day, week, month, and year.
Data warehouses, while extremely valuable to businesses, are expensive and time consuming to build and can be costly to modify over time. Much effort and time is required to define the business reporting required, the data needed to support it, the business rules to transform the data, and the optimal delivery methods. On the positive side, data warehouses are very efficient in terms of data storage and performance, which were considered very important benefits that helped justify data warehouses when they emerged in the 1980s, when computing power and data storage were very expensive resources.
Within the last decade, however, the concept of data lakes has emerged as an alternative to, or an extension of data warehouses. Like data warehouses, data lakes contain structured data transformed from source systems. But data lakes also contain vastly more information by copying raw data from source systems in its original structure; something that has become increasingly cost-effective due to ever-lowering costs of processing and data storage. Data lakes are also faster and easier to implement because they do not require the up-front effort to decide what data is important and how it should be transformed. Rather, they copy the data in its original structure so it can be used if and when a need is identified. These dramatically larger data lake repositories are essential to support today’s emerging artificial intelligence, machine learning, predictive analytics, and data visualization processes. However, data lakes also require the involvement of sophisticated data analysts and data scientists to transform, package, and deliver the data to end users in applications and interfaces that they can embrace.
Their use in law firms today
Compared to other industries, law firms have been relatively slow to adopt both data warehouses and data lakes. Only the largest firms have had the level of data volume and business needs for a data warehouse and fewer still undertook the significant investments needed to create and maintain them.
Today, firms with existing data warehouses are looking to expand them with the addition of data lakes. Firms that currently do not have data warehouses are considering which of the two approaches is the best solution. Fortunately for these latter firms, the two alternatives can be complementary rather than mutually exclusive. The real question is more properly, “Where should we start?” For many, the answer may well be to start with a data lake initially and move on to a data warehouse over time.
Pragmatically speaking, building a data lake will take significantly less time and effort because the only major decisions or design considerations are what data sources are to be included within the time frame of a specific project and how much data will be included from each source. Challenging business decisions like “How do we calculate profitability?” or “What details about a client really matter to us?” can be deferred to future data warehouse projects.
From a technical perspective, it can take less than one year for a single skilled technical data integration expert who is familiar with common legal and business systems to build a data lake that consists of the type of selected data shown above. Data warehouses, on the other hand, can become a multi-year project involving many people to represent selected, curated data due to the challenges of deciding which data to include, defining the business rules to clean that data, and applying those rules to data imports. As a result, six-figure costs for a data lake can easily become multi-seven-figure costs for a data warehouse.
Finally, starting with a data lake first offers three additional important business advantages:
- A data lake positions a firm to establish a data governance programme, which helps to get the entire organisation on board with managing data as an asset before confronting the challenges of building a data warehouse model.
- If a firm wants to engage data analysts or data scientists, either on staff or as consultants, a data lake can provide the data resources they will need to fulfil the firm’s goals and objectives.
- Finally, data lakes create a central repository for data that will make building a data warehouse easier in the future.
Conclusion
There is much discussion today in law firms around choosing between data warehouses and data lakes as a binary decision. Fortunately, such a singular choice my not be necessary—neither choice is mutually exclusive. For those law firms fortunate enough to have an existing data warehouse, a data lake can position them to move forward with the more advanced data needs of artificial intelligence, advanced analytics, and more. For firms just venturing into this arena, data lakes can provide a relatively quick start and offer near-term benefits that can build support over time for further investments in more focused data warehouses.
Whichever choice a law firm makes will really depend on where it stands in its journey to enabling effective data management platforms and where the firm leaders want to go next.
For more information on innovative legal technology, please click here.

By: Todd Painter
Data Practice Director at Fireman & Co.
Todd Painter is the Director of Fireman & Company’s Data Practice. He has worked to solve business problems through the use of data for more than 20 years, with the last 10 in the legal industry at Bryan Cave Leighton Paisner and Fireman & Company.
Painter also helps law firms and legal departments build data management programs, centralize data on premises and securely in the cloud, and use data to assist in answering the big business questions.
Prior to working with data for a living, he toured the world playing rock trombone and keyboards and now writes and performs music when he can find the time.



